Welcome to my blog! I’ve been working at what I call “industrial statistics” and exploratory modeling for almost 30 years. I’ve dealt with a large range of data types and problem situations, and I find that my colleagues regard my judgment and insight.
I’ve learned that having a breadth of technical knowledge is critical, but when such knowledge is wedded to good judgment or intuition about meeting the needs of a particular situation or data set, great things can happen. In this blog, I hope to impart some of the intuition I’ve accumulated.
I’m writing this for data analysts and those who work with them. I don’t assume technical knowledge, but I do assume interest in strategies for meeting challenges and understanding features of data-based decision-making. This is not a “how-to”, but rather a “why-to”.
Please comment if you feel moved. I’m interested to hear your perspective on the topics I’m discussing.
You can be notified of new posts in one of the following ways:
Subscribe to an e-mail notification.
From a Fediverse account (such as a Mastodon account), you can follow {at jimg at replicate-stats.com}. (Put this address in the format @user@site-name. I have to write it this way because this editor automatically converts it to the address to my author profile.)
Suppose you have reason to believe that a biomarker signal could precede a clinical diagnosis, leading to earlier and better intervention. You have a large collection of candidate biomarkers, and you think possibly a small number of them could form the basis of this predictive signal. You assemble a collection of clinical subjects for whom you take blood samples repeatedly over time. Some of them go on to be diagnosed; others never do, and leave the study.
This is almost, but not quite, a biomarker discovery / classification problem. Analysts have an enormous bank of biomarker discovery and classification tools, so we’re inclined to turn to those. But applying stock classification methods is forcing a round peg into a square hole: there is a resemblance, yet there are key differences, as I explain in the next section.
The biggest difference is that classification is appropriate when there is a clear, well-defined time to make a classification decision (or to decide that the case isn’t clear). Monitoring is appropriate when the question of when to make a call is very much in play.
I find that for the monitoring problem, there is not a tool that estimates coefficients straightforwardly, the way logistic regression does in the binary classification context. My proposal offers this; accordingly I call it “Monitoring Regression”.
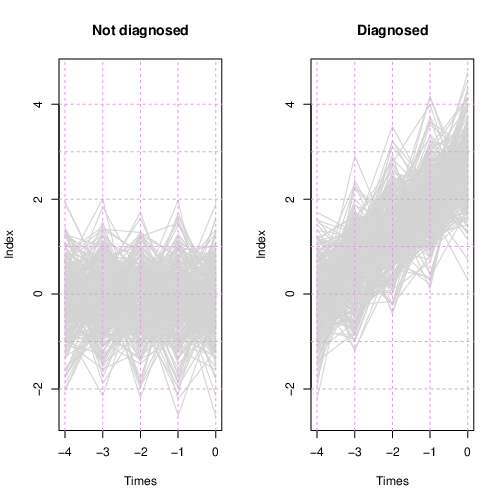
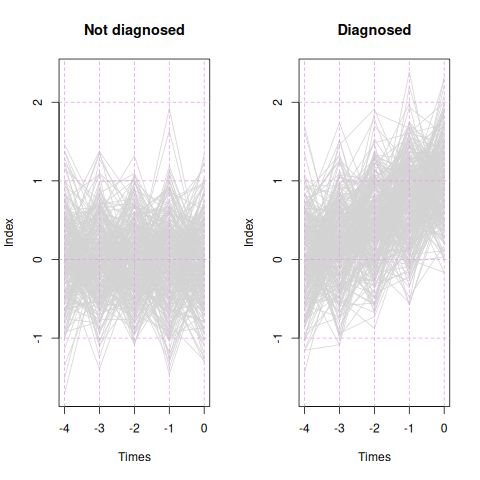
Here’s a teaser for the remainder of the essay: I simulated 600 hypothetical subjects with 40 biomarkers, each subject observed at five time points. 300 patients were diagnosed at the last time point, while the other 300 were not. Four of the 40 variables were informative for predicting the diagnosis, while the other 36 were not. The Monitoring Regression process I describe below selected the four informative variables, neglected the rest, and estimated a linear combination of the four, which Figure 1 shows for each patient, separately for the diagnosed and not-diagnosed groups.
Figure 1: Patient traces over time, by penalty and diagnosis status. Time is prior to diagnosis or end of study.
This essay is a high-level description intended for a non-statistical, yet interested, audience. I plan to submit a more detailed article for publication.
It would be grand to try out the method on a real-world example. If you have a suitable example, I’d be happy to do carry out regression fitting, and propose a follow-up monitoring program, for no fee, if I can use the example in publication. Some obscuring of data and identifying aspects of the problem so as to not give away key secrets are permissible. If interested, please contact me.
Related applications
An application related to biomarker discovery for diagnostic monitoring is monitoring signals over time, such as EKG’s or EEG’s. This would probably require some pre-processing or extension, such as applying a wavelet transform or fitting a neural net, or fitting a neural net to wavelet coefficients.
Another area is mining streams of telemetry sent by electro-mechanical systems in order to develop a monitoring regime to identify likely failures as early as possible.
The right method for the problem
The classification task, in clinical application, uses biomarker(s) to classify patients, usually as “Positive” or “Negative”. However, in many cases what the analyst truly desires is to find measurements that may be predictive when monitored over time. The monitoring and the classification contexts are distinct.
In a classification problem, data from each patient is complete and mature at a designated point in the patient’s time course (modulo some data imputation in real applications). We train a model to generate class probabilities, which can then support decisions of “Positive”, “Negative”, or “Uncertain”. (In some cases, the system doesn’t provide probabilities but simply makes class decisions directly.)
In the monitoring context, we have data available at multiple time points per subject, and at each time point the monitoring system determines “Positive” or “Continue monitoring”. It resembles classification except that determining the time of call is a critical aspect of the problem; most likely, we could make a call earlier, but less accurately; or later, and more accurately. Perhaps some patients could be called with high confidence at an early time, while others gain no time advantage at all.
Time alignment
Furthermore, the two contexts differ in time alignment. In classification, we assume that the question of when to attempt classification has already been answered. If data from prior time points is to be included in the classification, we assume that these data are comparable and complete. If time-series signals are used, they’ve been appropriately aligned. And so on.
Generally there needs to be a universal definition of “time zero”, relative to which all other times are expressed, either before or after. In some cases time zero is the time of entry to the study. However, if patients can be tracked for an indefinite and variable period of time, after which a diagnosis is made, then the time of diagnosis is the relevant benchmark, and we ask, “By how much time preceding the diagnosis can we make a clinically valuable call?” However, the benchmark of diagnosis time is not available for the patients who were never diagnosed. To apply classification methods, we have to come up with some benchmark for this group. Perhaps we choose a time randomly. Perhaps any time is as good as any other, or perhaps not. It’s problem-dependent. At any rate, there is no clearly appropriate time benchmark when a patient was never diagnosed, yet we must “make up something”.
Tendency to use classification methods
If a patient in a well-defined context appears in a clinical setting and the physician must make a decision at that time, then classification may be the appropriate tool. However, often the physician observes the patient over time, taking measurements in sequence, and has to determine when enough evidence has accumulated to justify intervention. This paradigm is better described by the monitoring context.
Even though many health decision-making questions better fit the monitoring characterization, analysts pursuing empirical methods almost always apply classification methods. There is an enormous set of tools available for the classification problem. Is there possibly an approach that more directly addresses the monitoring context?
Monitoring vs. longitudinal analysis
There is a branch of statistical analysis that deals with sequences of observations from subjects, along with other information: longitudinal analysis. However, most longitudinal analysis addresses estimates effects, and assesses evidence that those effects are not null, when multiple observations share an experimental unit, and therefore are not statistically independent. It’s generally retrospective; time courses are usually completed for all subjects before analysis occurs. It’s not designed to determine when to make a call and stop observing.
A cousin of longitudinal analysis is “joint modeling”. This combines a longitudinal model for biomarkers with a time-to-event model for outcomes, sharpening inference on the relationship between biomarker evolution and outcome. As the name implies, fitting a joint model is more complex and more computer-intensive than fitting either model separately. It does not directly address the question of when to intervene (and stop monitoring), nor selecting biomarkers from a large set of candidates, although development towards both of those goals has been done, with even more complexity and computation. The Monitoring Regression I describe below is simpler and addresses the monitoring question more directly; it could be a good precursor to inferential analysis with a longitudinal model.
Hidden Markov Models
Another analytical approach that supports statistical inference, and could be tweaked to accomplish monitoring with reasonable directness, is Hidden Markov Models (HMM’s). Here a subject is in one of several states; the state can change over time. At each time point we don’t know the state, but we see data given by the subject which (we hope) differs depending on the state. When evidence accumulates that the subject’s state has changed, we can make a call.
HMM’s don’t offer a convenient method to select variables from a large set of candidates. (With any model, one can try various subsets and arrive at a set, but this is usually cumbersome and leads to overly-optimistic sets.) This is where Monitoring Regression can contribute.
Avoiding complete density estimation
An additional motivation draws from an aspect of logistic regression in the classification context: logistic regression directly estimates the ratio of the class densities.
Let me explain. In classification, we look at data emitted by subjects which belong to an unknown class. It is differences in the probability distributions per class that allow for classification. One tactic for classification is to estimate the distribution of data from each class, based on the training data. Then when we see new data, we see which class’s probability distribution makes the observed data more likely. (Technically this is carried out via Bayes’ Rule.)
However, estimating distributions can be hard. What aspects of the distributions should we take pains to estimate accurately? Is a bump really a bump, or is it a chance occurrence—is the density unimodal or bimodal? Each artifact we estimate “consumes” data. Every question we answer empirically (e.g., number of bumps) consumes data. Yet these data-consuming aspects may or may not contribute to discriminating class differences.
With logistic regression, we avoid the question of estimating total class densities, and directly estimate where the densities differ (in their ratio), and in particular, where they differ in ways that can be most efficiently identified.
(A tip of the hat to Brian Ripley’s Pattern Recognition and Neural Networks, which planted this notion in my mind years ago. This book, published in 1996, illuminates critical concepts very well even if it is now very out-of-date technically.)
Longitudinal methods which can be pressed into service for monitoring, with some effort, address the total distribution. Where is the analog of logistic regression, which sidesteps the distribution-estimation aspect and directly searches for an effective function of candidate variables?
I envision Monitoring Regression filling that role.
Monitoring regression in a nutshell
When a carpenter assesses the straightness of a piece of lumber, he looks down it from end to end. This compresses the length dimension, allowing small shifts to become evident. In Monitoring Regression we’ll look down the pathway of each subject and try to discern features that separate one group from another in a way that doesn’t depend strongly on time.
Monitoring Regression includes two major components and a search algorithm that brings them together.
Coefficients determine an index
First, we have coefficients that govern the combination of candidate variables at each time point, independent of other time points. I refer to this combination as an “index.” The combination mechanism that first comes to mind is a linear combination, but in principle any transformation governed by parameters is possible. This includes extensions to linear combinations that we use in regression models, such as interaction terms and spline basis elements to model non-linearity. It also could include neural nets, which after all are are also determined by coefficients. Given the low signal-to-noise ratio and modest sample size typical of clinical biomarker data, I don’t expect a neural net to improve over a linear-combination approach, but at least it’s possible.
Goodness-of-prediction metric
Second, Monitoring Regression requires a metric that assesses (quantitatively) how well the identified function of variables relates to outcome. Below in this essay I describe a simulated example using a correlation metric that quantifies monotone relationship to amount of time prior to diagnosis. It’s important that the outcome for all cases can be encoded sensibly; for the “time prior to diagnosis” outcome I apply a small trick that the value is capped at some maximum value. Patients who are never diagnosed are given the capped value; this should make them comparable to diagnosed patients whose readings occur early enough prior to diagnosis that they are effectively negative.
The time cap must be based on subject-matter knowledge. Within what amount of time prior to diagnosis would biomarkers be expected to begin moving? If uncertain, one could try several time caps. The method should be robust to time caps that are a little too high; this will lead to including time points that are not contributing to any trend, which can be tolerated if there is a trend subsequently. The magnitude of trend will be diminished a bit but hopefully the index that maximizes the trend will remain the same.
In the simulated case below, I imagined that the time cap was four time units prior to diagnosis. Patients have data available at times
The values are negative because they represent time prior to diagnosis or end of study; as time progresses forwards, these values count down to zero.
If an index moves upwards monotonically over this time, we have a correlation between index and time prior to diagnosis of nearly 1.0. Meanwhile, for a patient who is never diagnosed, yet is tracked over the same time periods, their times “prior to diagnosis” are uniformly
All of their index values will be stacked at the same time point, the earliest one, along with the first time point for the diagnosed patients. Non-diagnosed patients have correlation precisely zero, because the correlation function is implemented to yield zero when one of the variables has no variability.
Evaluated individually, non-diagnosed patients have correlation zero, but together with other patients they can contribute to the aggregate metric. A modified correlation could allow for subject-to-subject variability (the correlation is implemented as a linear regression, which could accommodate subject-specific offsets). In this case, all non-diagnosed patients would contribute no influence to the aggregate correlation; however, all patients would require at least two time points. The index would be allowed to float from patient to patient, and only a patient’s change would matter.
Another possible metric is to calculate the maximum index value (over time) for each patient, and then evaluate a t-statistic comparing maxima of diagnosed patients to maxima of non-diagnosed patients. However, if trend is present during the time window, each point in time will contribute, making the trend assessment a more efficient metric.
Optimization
At this point we have an index to be determined (via as-yet-unidentified parameters) and a metric that assesses how an index relates to outcomes. We fit a Monitoring Regression model by finding the index coefficients that optimize the metric. Optimization in this context is harder than for multiple linear regression due to the analytical intractability of the metric function. With standard multiple linear regression, the set of coefficients that minimizes the sum of squared errors is accessible through a single matrix operation. However, the aspects of Monitoring Regression metrics that remove time from the calculation are nonlinear: the correlation metric uses the rank transformation, while the t-test of maxima involves, well, maxima. Both involve sorting, a non-linear operation.
A general multivariate search algorithm links the coefficients (defining the index) to the goodness-of-prediction metric. The Simultaneous Perturbation Stochastic Approximation optimization algorithm (SPSA) is relatively simple to implement; it’s also more efficient than most multivariate optimizers, because it uses only two function evaluations per iteration, no matter how long the parameter vector. (A third evaluation per iteration allows us to track progress.)
To be precise, high-dimensional searches are harder than low-dimensional ones. Saying SPSA is relatively efficient doesn’t make it fast or easy when applied to large problems; rather, it’s simply faster and easier than other methods. The key is that the number of function evaluations is fixed, regardless of problem dimension. The convergence rate is then whatever it is, and as dimension grows, the convergence rate slows accordingly.
However, SPSA isn’t critical to the application here. Any multivariate optimization routine that optimizes would work. It’s a question of efficiency.
Loss function
It’s prudent to not optimize for goodness-of-fit alone, but rather to embed the metric in a loss function that also includes a penalty for more-complex models. “Complexity” is usually represented by the total coefficient size (either absolute or squared). A penalty weight (usually designated by the Greek letter λ) balances the coefficient penalty against the goodness-of-fit metric. For the correlation metric, which must lie between -1 and 1, we must make sure that the weighted penalty does not exceed 1, otherwise setting all the coefficients to zero would trivially optimize the loss; a search for parameter values would be pointless.
In short, Monitoring Regression uses a mapping from multiple variables to a single real-valued index, as governed by parameters; a metric assessing the relation of the index to outcomes; and an optimization algorithm to find the index parameters that optimize the metric.
Statistical inference
Note that Monitoring Regression doesn’t provide statistical inference, such as standard errors for coefficients or a hypothesis test for inclusion of a set of variables. It is rather an “algorithmic” analysis tool, and should be regarded as such. Like k-means clustering, multidimensional scaling, or t-SNE (which serves the same function as multidimensional scaling), Monitoring Regression is a useful analytical tool that is defined algorithmically, based on reasonable statistical principles, but doesn’t have a basis in a probability-distribution-derived likelihood.
If one had to carry out statistical inference, nonparametric bootstrapping would be possible (resampling at the subject level).
Simulation example
Here is an application with a simulated data set. It is based on a few favorable assumptions for the method, but demonstrates that it can work.
Simulated data
Suppose we have 300 subjects who will be diagnosed and 300 who will not. From each subject we take 5 observations at time points
At each time point, for each subject, we measure 40 predictor variables. All are normally-distributed with mean zero and SD 0.5 except for the first four variables:
For these four variables, only for the to-be-diagnosed group, the mean begins at zero (for time -4) and progresses linearly to 1.0 at time zero.
Thus at time zero, the time of diagnosis, we have an effect size (mean difference divided by SD) of 2.0. If we tried to classify patients using only one variable with this effect size, at one time point (time zero), with a cutoff midway between the means (i.e., 0.5), our accuracy rate would be 84%. This accuracy rate is clearly higher than noise levels, but from a clinical diagnostic perspective, would be definitive. Could we do better by fusing multiple variables, and tracking them over time? (Spoiler alert: yes. I can’t say offhand whether it’s the fusing of multiple markers or the tracking over time that helps more.) I intend for this simulation problem to be feasible yet challenging.
Fitting the index
I applied the SPSA algorithm to search for an optimum linear combination, with an intercept term included. The loss function includes a penalty on the sum of squared coefficients (i.e., a ridge regression penalty) with a weight of 0.01. I’ve structured the problem as one of minimization.
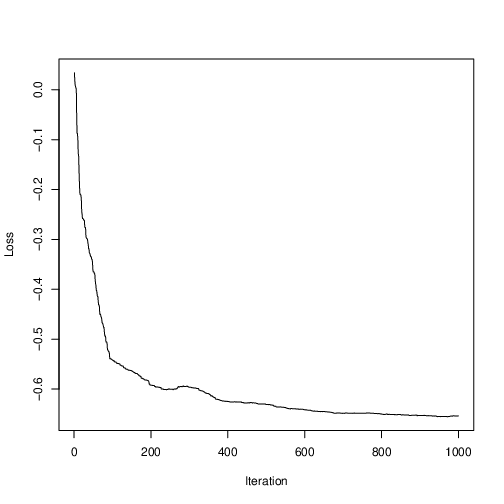
Figure 2: SPSA optimization trace. Improvement has occurred!
Figure 2 shows the loss values during the course of the optimization run; clearly some optimization has occurred, and progress has plateau’d. Being a stochastic optimization algorithm, it is not required to improve estimates at every iteration. In fact, Figure 2 shows that, for some iterations, loss increased. This is a healthy feature that enables SPSA to have a probability of bouncing out of inferior local optima, while an algorithm that is forced to take only steps that decrease loss would be highly likely to get stuck.
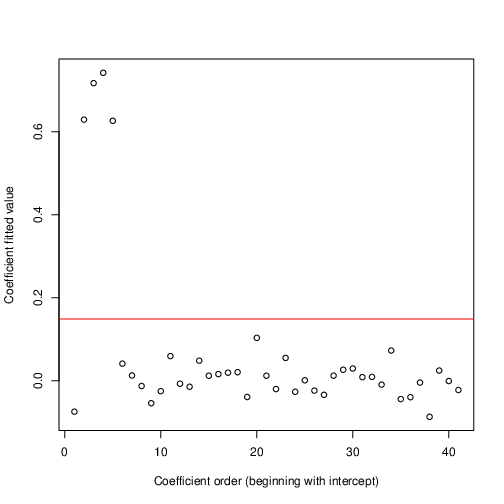
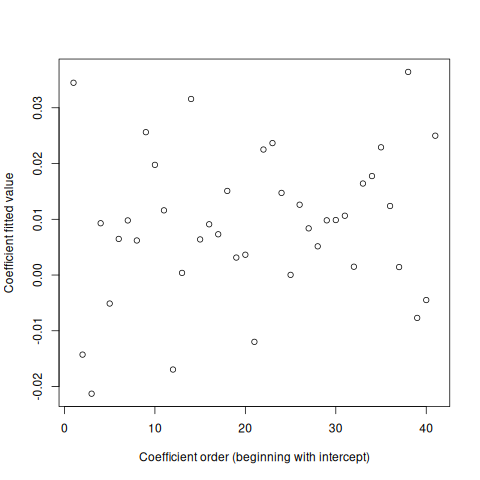
Figure 3: Fitted coefficient values in order, beginning with intercept. A 3-SD line is added, based on estimates robust to outliers.
Figure 3 shows the coefficient estimates that minimize the loss. Among the coefficients, the first shown is the intercept term; the next four are the coefficients that are truly informative; the rest are purely noise, according to the simulation. The horizontal red line is a 3-SD threshold where I estimated the SD with a method robust to outliers (the hubers function in R’s MASS package). The optimization has perfectly identified which variables truly contribute.
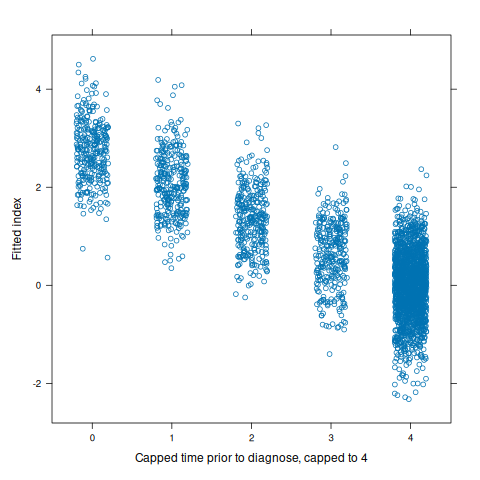
Figure 4: Fitted index values vs. capped time prior to diagnosis.
To clarify the behavior of the correlation metric for which the index is optimized, Figure 4 shows index values (with non-important variable coefficients set to zero) against capped time prior to diagnosis. Among all patients who are not diagnosed, this value is set to the cap, four. This is why many more points fall on four. The correlation coefficient (used in the loss function) for the plotted relationship is -0.866.
Assessing over-fitting
Why are the non-important coefficients in Figure 3 not estimated to be precisely zero? There are two possibilities.
First, SPSA is a first-order optimizer; it assumes local linearity. This can proceed towards an optimum point very quickly, but once the derivative-estimation gain constants span the optimum, the process is apt to bounce around near the optimum until the control sequences decay to zero. It’s like water spiraling down a drain; the water has reached the drain but can’t directly drop through it. A second-order process would estimate local curvature and, based on that, hop very close to the optimum point. Such an analog to SPSA exists but I haven’t tried it yet. Future work!
Also, SPSA is a stochastic optimizer. It makes random choices at every iteration. This can be very efficient. However, it means that at any given point in the process, if it has stopped making progress, we can’t be certain that it simply hasn’t yet found a path for improvement. With more and more iterations, such a possibility becomes less and less likely. But at any given moment, there is some uncertainty.
Second, it’s possible that small nonzero coefficients actually yield smaller loss than zero-valued coefficients. This would imply a degree of over-fitting.
The “best” value that SPSA found was -0.656, associated with many coefficients close to, but not equal to, zero. If we set the non-important coefficients all the way to zero, the loss is -0.657, 0.001 smaller. So there exists at least one parameter vector that beats the best that SPSA found (but we used SPSA to find it); if SPSA continued, it would converge to that value, or to a still-better one. We still can’t know if the absolute best sets coefficients to precisely zero. However, perfect can be the enemy of the good; we’ve solved our problem, because we’ve identified important variables and obtained good coefficients for them. Whether we zero out the remaining coefficients isn’t critical; for operational purposes at least, in most applications, we would do so.
I’ve repeated this exercise with both LASSO and ridge penalties, and with different penalty values, and these choices make little difference. The ridge penalty tends to move the four meaningful coefficient estimates closer together; this is typical behavior for the ridge penalty. It’s also optimizes more smoothly.
I’ve also tried optimizing with no penalty at all, and the optimization still leads to identical overall conclusions. However, I retained the small penalty weight of 0.01 out of principle.
Performance
Now let us calculate the identified linear combination using the four fitted coefficient values, setting the rest to zero, and applying the calculation to all observations from all subjects. Figure 1, shown in the introduction, shows traces for every subject in light gray. For the non-diagnosed subjects, the linear combination exhibits noise around zero at all time points. For the to-be-diagnosed subjects, at time -1.0 the linear combination is centered at zero with noise, and it grows linearly from there.
The apparent “bumpiness” at the five evaluated time points is an artifact of regression to the mean: values that happen to be in the extreme tails fail to repeat such at the next time point, giving what appears to be a saw-tooth pattern.
At some time point prior to diagnosis, a clinician should be able to monitor $$X\hat{\beta}$$ and at some time point he or she could confidently say that diagnosis is likely in the future. I’ll speak to that in a follow-up essay.
For the moment, please note that retrospectively identifying that the index is worth monitoring doesn’t address the specifics of how decisions based on the index would best be made.
The identified index could also be analyzed using other tools for longitudinal data, such as joint modeling, HMM’s, or generalized least squares. If analysis (rather than clinical monitoring) is the goal, Monitoring Regression could serve as a useful precursor to these inferential methods. Of course, using the same data twice—first to identify variables and fit an index, and second to do statistical analysis with a probabilistic model—introduces bias into the latter. A prospectively-gathered follow-up dataset is warranted.
The value of an index
Suppose we correctly identified that the first variable is important, but we only identified this one. Using this variable alone to monitor patients, we would see this analog of Figure 1:
Figure 5: A separation plot using the first meaningful variable only.
The overall look is similar, and evidently there is some utility in monitoring, since the diagnosed patients show an upwards trend prior to the time of diagnosis. However, if we closely compare Figure 1 to Figure 5, we see that Figure 1 exhibits much better separation between non-diagnosed and diagnosed patients than does Figure 5. This accrues to Figure 1 being based on a synthesis (specifically a linear combination) of all four meaningful variables.
Negative example
The example above tests Monitoring Regression with known useful variables, and in that case it did well. Completeness demands that if a data set contains no useful variables, it should lead to a null conclusion.
Therefore I repeated the simulation as before—with 300 diagnosed patients, 300 undiagnosed patients, and 40 variables observed at each of five time points—except that all 40 variables are mean zero. No variable is informative. Nothing trends over time. Does my implementation of Monitoring Regression lead to the correct conclusion?
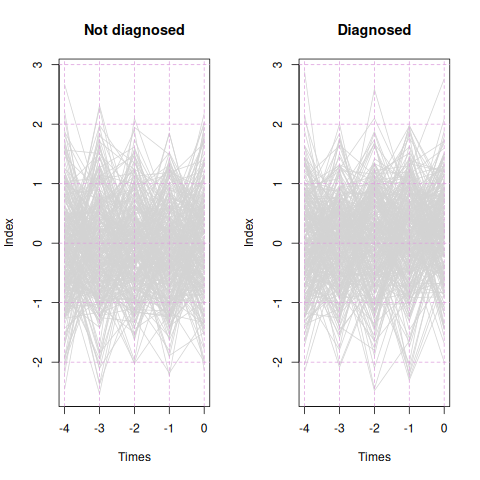
Figure 6: Coefficient estimates for a simulated data set in which no variables (out of 40) are important.
Happily, it does. Figure 6 shows estimated coefficients. They are all close to zero and none stand out; none exceed the robust 3-SD limit. While we don’t have a statistical inference to assure us, we can assess that the coefficients are small relative to the range of the variables. (In practice we should standardize all variables to ensure that we penalize coefficient magnitudes equally, so we could determine what makes a coefficient too small to be meaningful; I’ve neglected that here because I know all the variables have the same scale.)
Figure 7: Fitted index traces for all subjects in the null example.
However, the real proof is whether the fitted index trends upwards for diagnosed patients and does nothing for undiagnosed patients. Figure 7 shows the patient traces. The diagnosed patients show no trend, just like the undiagnosed patients. The fitted index has no utility. Therefore we can be assured that if the data set has nothing happening, Monitoring Regression is unlikely to find something spurious.
Relation to Cox proportional hazard model with time-varying covariates
(This section is intended for a statistical audience.)
The astute statistical reader might ask whether Monitoring Regression is almost equivalent to the Cox proportional hazards model with time-varying covariates. The Cox model finds a linear combination of predictor variables that maximizes a concordance with outcome frequency.
More specifically, it divides time into intervals based on the times at which either an event occurred for some subject, or a subject left the study. Usually there are many such time points. (The fact that multiple intervals accrue from the same subject is ignored.) The Cox model treats the intervals essentially independently; one has a collection of intervals, each with its covariate values and its number of events, and based on that collection, a linear combination is sought which discriminates the intervals with more events from the intervals with fewer. With time-varying covariates, the covariate values within this collection of intervals may vary, even within subject. If the covariates do not vary over time, they may vary by subject, but are constant among intervals accruing from the same subject.
By default, the Cox model does not comprehend continuous change in covariates from previous time points. To add such effects, one can add lagged variables, or calculate change from earlier points.
In the simulation set-up used above, every subject is observed at each of 5 distinct and equal times. The only events that occur do so at the fifth time point. To identify covariate effects that predict risk of the event, the Cox model with time-varying covariates would evaluate covariate values at the fifth time point. An elevated value of x1, for instance, at the fifth time point, in a subject who is diagnosed, would tend to increase the coefficient value for an x1 effect. However, in that same patient, their x1 values may be elevated at the third and fourth time points, but since no diagnosis occurred then, these values tend to decrement the association of risk with elevated x1.
We could add lagged variables, or calculate change from the previous time. This would help a Cox model estimate that not only does x1 elevated at the fifth time increase risk, but that increase since the fourth time increases risk, and elevation at the fourth time point also adds to risk assessment.
However, similar data at earlier time points will partially mask these effects, since no events occurred at those times. In fact, the most effective Cox model would include all time points as lagged data at the final interval, in order to properly estimate risk as a function of a subject’s total trajectory. This would eliminate masking due to time intervals in which covariates are trending yet no event occurs. However, this would induce many problems:
In typical use, we cannot count on having an equal number of time points per subject.
The lagged model adds many variables, even though the goal of analysis is to find a set of variables worth monitoring using values available at the current time.
Monitoring Regression directs attention precisely at the monitoring problem and so is able to find a simple system. At every time point, Monitoring Regression uses only covariate values at that time. Trends are comprehended in the optimization metric rather than in the model itself. If one seeks a set of variables, and a function combining them, that uses only current-time values, yet is worth tracking over time, Monitoring Regression provides that directly.
Summary
Monitoring Regression takes a direct “model-free” approach to identifying variables that, in combination, can support monitoring to detect cases trending towards an event. I refer to “model-free” in quotes because the system does make some assumptions, which should be checked, but a probability distribution is not one of them. It could be a useful addition to the toolbox of any data analyst looking at sequential data with a monitoring perspective.
This essay goes out to statisticians who are wondering how Machine Learning (ML) compares to classical or parametric statistics, whether it will affect their jobs, or what role it should have in their current work.
I recently presented some thoughts at the International Alliance for Biological Standardization’s annual statistics conference; the audience was primarily statisticians supporting pharmaceutical manufacturing. The conference was small and familiar; there was plenty of free-form discussion. In that discussion, questions about ML and its place in manufacturing (in a highly regulated context) surfaced repeatedly.
Is “machine learning” a statistical endeavor?
Is ML statistics? Should a statistician use ML tools? If so, when, or when not? Could ML tools work effectively on data coming from sparse designed experiments?
As someone who treasured his copy of Hastie, Tibshirani, and Friedman’s The Elements of Statistical Learning when it first came out, there is no question in my mind that ML is statistical. It says “statistical” right there in the title! And the authors are statisticians, academics employed in statistics departments. Further, the discussion is founded on probability and leans heavily on statistical concepts and model-fitting principles (e.g., the classic bias vs. variance trade-off and optimizing penalized likelihood).
Ripley brings together two crucial ideas in pattern recognition: statistical methods and machine learning via neural networks. He brings unifying principles to the fore, and reviews the state of the subject. Ripley also includes many examples to illustrate real problems in pattern recognition and how to overcome them.
Therefore I’ve never had any doubts that ML can be viewed and handled effectively through a statistical lens. Indeed, I’m convinced that a statistical lens is very much the most effective lens to use.
That last statement may sound tribal—“Statisticians are the best!”—but that isn’t my intent. Rather, it’s a tautology, at least in the framework I’m using.
I consider statistics to be the study of making decisions based on noisy data. The theoretical grounding for statistics is in “decision theory,” which is game theory in which your opponent is Nature. Nature’s move in the “game” is to determine a state that is unknown to you, while the statistician’s move is to make a decision whose loss depends on Nature’s unknown state. But first, you get data. How do you use that data to make a decision? The mapping from the data to your decision is a “decision rule,” otherwise known as a “statistic”. The questions of theoretical statistics concern optimal decision rules, and why they are optimal.
Put more bluntly, statistics is the study of what makes decision-making based on noisy data work well. Therefore if some technique or idea works better than “standard” statistical methods, it’s incumbent on statisticians to verify that the new method is superior, identify why it works, and update the current state of the art accordingly, much as physicists had to expand beyond Newton’s laws when Einstein’s theories were experimentally verified. Then the new ideas, whether they originated from a statistician or not, become part of the world of statistics. That’s the case in an ideal world, at least, which may take some time to manifest. (As it does in science as well!)
So, when I assert that a statistical lens is the most effective lens through which to view ML, I’m really asserting that we need to bring all we know about how model-fitting can be made to work well to new (to us) methods in ML. And we do indeed have a few tricks to offer.
A hierarchy of modeling needs
We have to judge any model relative to what we want to accomplish with it. Here I’ll borrow shamelessly from Maslow’s Hierarchy of Needs, with apologies.
Faithfulness to data: All useful models need to predict well in the sense that we can feed in specific cases and get predictions that match actual responses to within expected error. We expect this even of models that we don’t intend to use primarily for prediction. If a model fails to be faithful to the data, all else is moot–in fact, interpreting such a model could be dangerous.
Variable importance: We may want to know what predictor variables are important in contributing to the response.
Quantify relationship: We may want to quantify how much an important variable contributes to the response (or to the mean of the response distribution). This is usually expressed as saying that a unit change in the predictor induces some change in the (mean of the) response.
With linear models the fitted slope provides this, but this concept generalizes to smoothly non-linear contributions. In this case the change in response would vary depending on the starting point of the contribution: for men 5 feet tall, an inch increase induces such-and-such a change in mean response, but for men 6 feet tall, the induced change is much less, for instance.
Statistical evidence: We may want statistical evidence that this effect is not nil, sufficient to convince a skeptical audience, such as regulators, article reviewers, and perhaps business leadership. Or we may want confidence intervals or equivalents which indicate how precisely we think we know the quantities.
Certain ML methods address some of the needs above. All should address the faithfulness need. Many will address variable importance (and anyway there are ways to assess variable importance from black-box models). GAM’s and MARS allow for non-linear relationships but allow slopes to be assessed visually (or computationally). GAM’s can provide approximate statistical evidence, although any statistical evidence is questionable when it comes at the end of an exploration involving many variables.
There are contexts in which ML satisfies an important need; one needs to simply use the right tool for the right context.
How does machine learning fit within the practicing statistician’s toolbox?
If I view ML as statistical, how do I blend ML with my other statistical tools? When do I reach for Random Forest, or MARS?
Here are the contexts for which for which I would consider turning to ML:
When there is a strong possibility of a complex mapping between predictor variables and the response. By “complex” I mean interactions among predictors, and I have enough data that identifying a complex interaction seems plausible; also, likely non-linear contributions from predictors.
Or, I have very little domain knowledge which can give me confidence that interactions are not present, and that contribution relationships are not non-linear. ML provides assurance.
Having any hope of modeling complex relationships requires substantial data. Therefore I would not entertain a ML model with a small number of cases.
There is a bit of nuance here. MARS can devolve gracefully to linear regression modeling when there aren’t enough cases to support further expansion.
Neural nets and SVM’s can fit small data sets, but in order to determine how well they fit, and to make intelligent choices about key questions such as the number of hidden nodes and the roughness penalty (weight decay), we need more data.
Tree-based methods simply need sufficient data to fit anything reasonable.
When there are many predictor variables, especially when there is a possibility that some of those may contribute to the response in a non-linear yet smooth way. Tree-based ML methods can do a good job of identifying important predictor variables.
Note that if you have many predictor variables about which you have little prior information or expert knowledge, statistical inference about specific variables will be highly fraught regardless of the method you adopt.
Wait, what about Bayesian methods such as Bayesian Model Averaging and inference with so-called “horseshoe” priors? Yes, these provide a reasonable inference, but it isn’t straightforward to include non-linear components. This is an area meriting further research and development. Assuming that every predictor contributes linearly is simply not a viable plan. My opinion might be in a minority among statisticians but I’m standing by it.
Looking over this list, I see a theme. ML models are flexible and make fewer assumptions about relationships. I lean towards ML if one is exploring and has a generally low state of knowledge. There are many candidate predictor variables, and one doesn’t know exactly what they mean, which are important, and whether their contribution is linear, or over what range. There may be complex interactions. In this context, ML can answer some basic questions quickly: Can the predictors predict? How well? Which are important? Over time and additional experience one may learn which variables are important, whether they contribute linearly or with what other pattern, and which interactions are certainly not present. As knowledge of this sort grows, a parametric (or semi-parametric) model becomes more appealing.
This presupposes that you’re dealing with “found” (i.e., observational) data. If one can design experiments prospectively, we have ways of addressing these early questions much more effectively.
Can ML/AI deal with designed experiments?
One question I’ve been pondering (successfully, I think), and which surfaced at the conference, was: can ML deal with designed experiments?
We are told that AI, and by extension ML, have enormous potential to optimize systems. Yet some of us have been optimizing systems successfully for decades. Are we missing something? Has AI come up with a wholly new way to go about this? Are we missing something?
I contend that traditional statistical design and optimization will continue to have value. Moreover, in many cases there is no benefit to fitting a ML model rather than the sort of models we have been. I’ll outline the features of those cases when there would be a benefit to using ML.
It helps to know a little about how optimization works. If you ask a computer to carry out a search for an optimum, what does the computer do? Of course there are many optimization algorithms, and there may not be one that works best for all contexts, but very of them have a simple foundation: approximating a surface locally by a simple polynomial (linear or quadratic):
Pick a location (vector of parameter values).
Identify the gradient (first derivative). This can be done analytically, if an analytic first derivative is known, or it can be estimated numerically by evaluating the function of interest at locations very close to the starting point.
In some cases a second derivative is found.
Either implicitly or explicitly, use the derivatives to approximate the surface locally by a first- or second-order Taylor approximation.
In the linear case, this indicates a direction of improvement. Move in that direction by some regulated amount.
In the quadratic case, the approximation may support an optimum point. Move towards that point, perhaps by a regulated amount.
Repeat until convergence; hope for convergence rather than divergence!
Note: It isn’t necessary to estimate the surface globally; it’s sufficient to have a series of good-enough local approximations. And Taylor’s Theorem tells us that the surface, if smooth, can be approximated locally by linear or quadratic models.
Statistical experimental design (i.e., “Design of Experiments”) also works by finding a series of linear approximations that move one towards an optimum. Then, if one uses response-surface methods, we use a quadratic polynomial to make a local approximation that tells us where the optimum is estimated to be, and also models the neighborhood around that optimum (which supports tolerance regions).
As with numeric optimization algorithms, at no point is a global estimate of the surface required.
Furthermore, it is often the case that the process under study is very expensive to evaluate; each run may cost multiple thousands of dollars. Therefore we pick runs extremely judiciously. In this case we create very sparse designs. It’s not unusual that the design is only just big enough to fit a specific linear or quadratic; these are “saturated models” which have as many polynomial parameters as design points.
Putting this all together, my recommendation is as follows:
If you already have a large data set of experimental conditions and their associated outcomes, use an ML model to allow prediction of future cases at any location in the design space. Then you can attach a search algorithm to find optimum conditions, or carry out designed experiments in silica. Since we must model the whole space, we can’t rely on a local approximation. We must use a model that is capable of being complex.
If you don’t have a large data set in hand, but will have to carry out experimental runs in order to explore the design space, statistical experimental design is the way forward.
In analyzing data from these designs, use traditional methods, which are based on first- and second-order polynomials.
If you have a problem with special features, you still have to put on a statistician’s hat to decide the best design points to run.
Given data from a sparse design, an ML model will not improve on the polynomial. In fact, often there won’t be enough design points to allow differentiation from a polynomial model. For example, the optimal design points to fit a quadratic model in one factor has three locations: low extreme, high extreme, and middle. In this (trivial) example, there is no data to support departure from a quadratic.
Sparse response-surface designs are similar, and so are sparse designs designed intended for early exploration (e.g., Plackett-Burman and fractional factorial designs). There simply won’t be a benefit to using ML.
What does it mean if a ML model fits better?
Let’s return to the question of a poorly-fitting parametric model and a well-fitting ML model. An ML model generalizes parametric models in three ways:
It allows for non-linear relationships between predictor variables and response.
It allows for interactions. Some (neural net, SVM, Random Forest) allow for arbitrary interaction. A few (gradient boosting, MARS) allow for a maximum degree of interaction to be specified.
Some ML methods can automatically combine “diffuse” effects and then operate on them non-linearly. A classic example is gene expression; researchers often collect a large number of gene expression values, and we don’t expect one or a handful of genes to be powerful predictors. Rather, we expect multiple genes to express similar information, in a context of overall high variability. Regression models can combine multiple genes in a linear combination; a neural net does this and then can apply a nonlinear transformation to the linear combination. (See also projection pursuit regression and sliced inverse regression.)
As I said above, there’s no magic here. If a parametric model is inferior to a ML model, it’s because the ML model is tracking the data in some attribute for which the parametric model is too restricted. And the possible generalizations are the three above. So the data set follows one or more of these attributes.
However, each of these three attributes can be addressed with a wholly statistical tool set:
GAM’s allow continuous predictors to make additive contributions via smooth non-linear (or linear) functions. Regression models with spline components—so-called “regression splines”—can also work.
Regression splines control curve roughness by limiting the size of the basis rather than with a fitting penalty.
An interaction term can be added to any additive model. We simply need to know what predictors the interaction involves.
There can be a challenge in finding interaction terms.
A multitude of diffuse predictors can be combined into an index via principle components analysis prior to modeling, among other methods.
A ML model does all this, quickly and in one step (from the analyst’s point of view).
In this research area, the word “interpretable” in “interpretable ML” means exactly what it says. While this term doesn’t have a precise definition, examples of models presented as interpretable include:
Lists of univariate rules combined with “and” and “or” logical statements.
Dr. Rudin makes several very interesting points within the two papers above:
In almost all cases of predictive modeling, an interpretable model can be found that predicts as well as a complex “black-box” model.
Finding the simple model that predicts well may require sophisticated optimization algorithms, techniques that are not in common use today.
This doesn’t apply to image processing and text-oriented large language models, but there is potential for special interpretable approaches in these areas.
In almost any realistic classification or scoring problem, there are many models that fit approximately equally well. Some are complex but some are interpretable.
When noise in the response is high, the possibility of many equivalently-predicting models grows.
…and Generalized Additive Models for the win!
At the IABS statistics conference, conversations indicated that there is a widespread presumption that ML models generally predict better than the models statisticians typically fit, which is to say, parametric models. (And, the presumption continues, we should use parametric models anyway, because they’re interpretable.) I’ve long argued that this presumption is not generally true, though it may frequently be true. Dr. Rudin takes it a step farther and argues convincingly that the presumption is almost never true: in almost every practical case, there exists an interpretable model that predicts as well as the best ML model.
However, the high-performing interpretable model(s) might not be a simple parametric model. Among the classes of interpretable ML models that frequently predict well is the Generalized Additive Model, possibly with some interaction terms. That is, extending the standard parametric model in one or more of the three methods discussed in the section above, What does it mean if a ML model fits better?
Why is the presumption of ML predictive accuracy so pervasive? I have my suspicions:
The most commonly-used statistical modeling methods—linear regression or generalized linear regression models—often don’t predict very well, because relationships often occurring in Nature are smoothly non-linear. Meanwhile, ML models often do predict well.
But why do we suffer models that don’t predict well? I believe we’ve been distracted by hypothesis testing. Typically, even if a relationship is smoothly non-linear, a hypothesis test that assumes a linear approximation will still give very strong evidence of a relationship, not least because it gives only one degree of freedom to the effect in question. Thus there is a statistical rule of thumb that linear is “good enough” for practical purposes. But we forget that that “purpose” is testing, and this isn’t always our purpose!
AI and ML often do predict well. Nothing in this essay claims that AI/ML doesn’t predict well, and I believe Dr. Rudin’s research doesn’t claim this either. The ability of AI/ML is not in question; that of the alternative’s is.
There is an enormous amount of money behind AI. There is of course a lot of hype, and no small amount of that hype is driven by money, and hope, and desire, and news attention, and desire for that attention.
“Neural nets can do things multiple regression cannot, therefore neural nets are more capable, therefore they must be able to predict better in classical regression contexts.” This does not logically follow, yet it is a seductive and enduring fallacy. Just because New Shiny Tool B does something that Old Tool A cannot do does not imply that Shiny B can do Old A’s traditional job better. Maybe A and B excel at different tasks.
This is the motivating principle behind a large number of published articles comparing the predictive accuracy of neural nets to logistic regression on clinical trial data. This literature has failed to find a consistent general advantage of neural nets, yet researchers continue to try.
Where this is all winding up is something that deserves a name. I’m going to call it the GAM principle:
Additive models
- with smoothly non-linear contributions from continuous predictors...
- and appropriate interaction terms (if we can find them)...
- and, for many diffuse predictors, indices combining them into a "latent" predictor...
...can predict as well as ML models, very often.
I use the term “GAM principle” rather than simply “GAM” because a GAM is a bit more specific: it refers to an additive model in which some or all of the continuous factors contribute via smooth functions. These are modeled using smoothing methods, smoothing splines or LOESS. (Nowadays splines seem to predominate.) “Smoothing” with splines involves creating a very large set of basis elements and limiting complexity via a penalty. Alternatively, one could augment a linear model with a more limited set of spline basis elements, and control complexity by the number of basis elements. We refer to this as a “regression spline” model. A regression spline satisfies the GAM principle but is not strictly a GAM. MARS similarly generates a limited set of spline basis elements, and satisfies the GAM principle.
The GAM principle implies that statisticians can fit interpretable models that are well within the statistics tradition, and predict as well as other ML models, but such statisticians will not be able to do this in a business-as-usual manner. They’ll need to familiarize themselves with GAM’s, regression splines, and/or MARS, if they haven’t already. In my experience, most statisticians have not.
I can’t help feeling smug. My very first blog post in this space made essentially the same point! In that blog I tell a story about statisticians delightedly passing around a research paper documenting that logistic regression fitted to clinical-trial data predicted as well as neural nets. Hooray for our side! Yet when I read the article, it referred to splines in the model, putting it in the GAM class. However, I’d never seen any of my colleagues who were so happily taking credit use splines or GAM’s. These statisticians were claiming a victory which wasn’t really theirs.
My familiarity with splines is partly motivated by Frank Harrell, Jr.’s book Regression Modeling Strategies, in which he advocates for using splines in models whenever possible. (“Possible” meaning “there are enough degrees of freedom available.”) His advocacy implicitly confirms that he has seen many data sets in which relationships were smoothly non-linear. Indeed, most of the book’s examples showed as much.
In my own experience, I routinely transform continuous predictor variables towards normal, and I find a transformation is warranted in more than half the cases I’ve seen. In modeling, I’ve only rarely found statistical evidence for a non-linear contribution from a transformed predictor. However, because often the predictors were transformed non-linearly, their “linear on transformed scale” contribution should be regarded as non-linear. My experience therefore aligns with Dr. Harrell’s, in a way.
Now I’m seeing Dr. Rudin’s work, and Dr. Harrell’s experience, and my own experience all aligning: models that satisfy the GAM principle are powerful, statistical, and interpretable ML. I’ll be more likely to try a GAM-type model in the future!
A technicality about interpretable ML
By advocating for GAM’s and/or regression splines, I’m laying a claim to interpretable ML that published practitioners in the field might contest. This is because statisticians fit models differently than in the published interpretable ML literature.
It depends on the type of model, but often they use exhaustive search to find parameters that allow the models to fit observed data. For instance, Rudin describes the logical-rules-generating algorithm CORELS; it searches every discrete value of every variable to evaluate possible rules in order to optimize classification agreement with known truth, plus a penalty per each rule.
We statisticians are accustomed to maximizing a likelihood function, or using likelihood in a Bayesian calculation, or simply using statistical measures to guide choices. We don’t optimize classification performance directly. And I think there are reasons not to do so.
I’ve been in too many meetings discussing cutoffs for assays in which someone argues for moving a cutoff a bit to catch one more single point, increasing the assay’s putative sensitivity. But we don’t care about that point: we care about the next point, which we haven’t seen yet.
Based on experience with cutoffs, I’ve argued for fitting densities to assay signals from populations of negatives and positives and then optimizing those smoothed distributions, rather than hashing over individual observed points. A smoothed ROC curve, if you will. Such smoothing generally improves performance and generalizability where it is applied. I expect that a similar logic would improve interpretable ML optimization methods. (The challenge is in the smoothing, though.)
Still, strictly speaking, I can’t claim to be using interpretable ML of the soft that’s been published as such, if I’m not optimizing models as the publications indicate. Fair enough, but I propose that statistical model-fitting will perform as well. I contend that it’s the type of model that’s used that matters, more so than the method of fitting.
But I’m picking nits. Consider what Dr. George Box said, after saying that all models are wrong but some are useful:
Since all models are wrong, the scientist must be alert to what is importantly wrong. It is inappropriate to be concerned about mice when there are tigers abroad.
If you like, enter your e-mail address and you’ll receive an e-mail whenever I publish a new essay.
I won’t give your e-mail address to anyone.
You won’t receive a notification more than once per week. I can’t write faster than that! I don’t publish on a fixed schedule; you should see a notification every two or three weeks.
Leave a Reply
You must be logged in to post a comment.